Contexte

Le contexte général de ce billet est celui du métrologie/monitoring domotique dont l’objectif est 1) de stocker dans une base de données des relevés horodatés (timestamp) de sources et de nature diverses (température, luminosité, détection, compteur…) ; et 2) de produire des graphiques en utilisant ces données.
Ces relevés sont des données singulières pour une base de données. Il est donc important de se poser des questions à leur sujet comme : Comment les traiter ? Existe-t-il ou faut-il utiliser un SGBD particulier pour les traiter ? Quels outils utiliser pour les explorer en produisant des graphiques ?
Particularités des séries chronologiques
Problématique
Les relevés que la base de données va devoir stocker sont particuliers et sont caractérisés par au moins :
- Un horodatage (timestamp)
- Une source permettant d’identifier l’origine de la mesure
- Une métrique permettant, entre autres, de caractériser la nature de la mesure
- Une valeur
De plus, ces relevés vont produire une grande quantité de données immuables. Par exemple, une centaine de capteurs avec en moyenne une mesure toutes les dix minutes vont produire plus de 5 millions de relevés par an. En principe, ces données ne sont jamais modifiées après insertion.
Il faut noter que dans ces données, la caractéristique horodatage est centrale : elle constitue un critère de tri et d’accès particulier qu’il peut être pertinent d’optimiser.
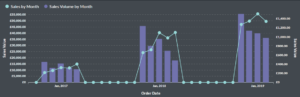
Enfin, il est souvent nécessaire de réduire la résolution de ces relevés chronologiques pour les afficher. Or cette réduction n’est pas triviale et fait intervenir des fonctions mathématiques pour produire des comptages, des moyennes, des interpolations, des lissages, des maximums, des minimums…

SGBD relationnel ou SGBD dédié ?
Pour trouver de l’information sur Internet à ce sujet, on peut utiliser les mots-clés suivant :
- Time Series Database
- Bases de données de séries chronologiques
- Bases de données de séries temporelles
Une petite recherche sur Internet permet de se rendre compte qu’il existe des SGBD dédiés, mais que l’on peut aussi utiliser un SGBD relationnel classique.
(suite…)





 Enseignant à l’institut universitaire de technologie de l’Université de Paris 13, lorsque le cours de
Enseignant à l’institut universitaire de technologie de l’Université de Paris 13, lorsque le cours de 

