
Ontology-based semantic annotation: an automatic hybrid rule-based method

In the perspective of annotating a text with respect to an ontology, we have participated in the sub-task 1 of the Bacteria Biotopes BioNLP Shared Task whose aim is to detect, in the text, Bacteria Habitats and associate to them one or several categories from the Onto-Biotope ontology provided for the task.
We have used a rule-based machine learning algorithm (WHISK) combined with a rule-based automatic ontology projection method and some rote learning. The combination of these three sources of rules leads to good results with a SER measure close to the winner and the best F-measure.
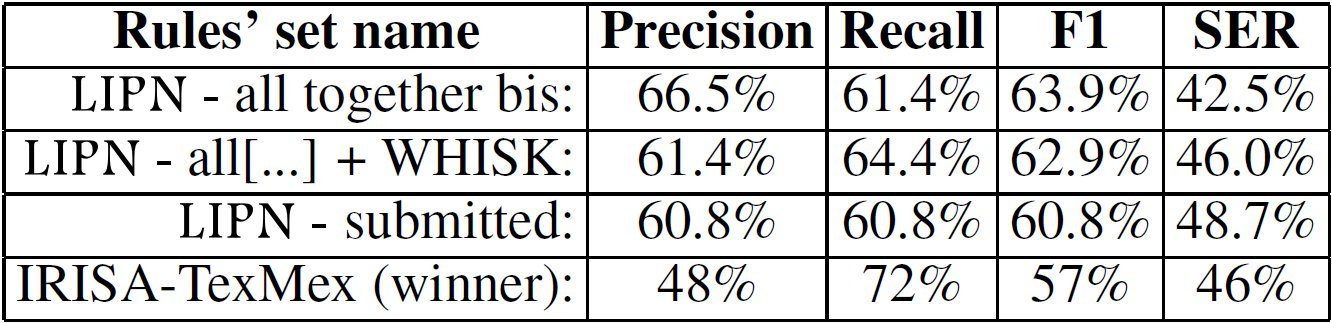
The sub-task 1 of the BB BioNLP-ST ranks competitors using the SER measure that must be as close as possible to 0. We are quite close to the winner with a SER of 48,7% against 46%. Our F-measure (60,8%) is even better than the winner’s F-measure (57%). Without our mistake, we would have been placed equal first with a far better F-measure (62,9%).
12/12/2014 … finalement premier ! — Une erreur s’était glissée dans l’implémentation de la mesure SER des évaluateurs. Finalement, le LIPN (nous) est premier. Plus d’un an après, cela n’a hélas pas la même saveur…
L’article Ontology-based semantic annotation: an automatic hybrid rule-based method sur HAL
BioNLP Shared Task 2013 (Hosted by the ACL BioNLP workshop Workshop)






{kind=link}